Comparing Elixir vs Java
- Attila Sragli
- 14th May 2024
- 31 min of reading time

After many years of active development using various languages, in the past months, I started learning Elixir. I got attracted to the language after I heard and read nice things about it and the BEAM VM, but – to support my decision about investing time to learn a new language – I tried to find a comparison between Elixir and various other languages I already knew.
What I found was pretty disappointing. In most of these comparisons, Elixir performed much worse than Java, even worse than most of the mainstream languages. With these results in mind, it became a bit hard to justify my decision to learn a new language with such a subpar performance, however fancy its syntax and other features were. After delving into the details of these comparisons, I realised that all of them were based on simplistic test scenarios and specialised use cases, basically a series of microbenchmarks (i.e. small programs created to measure a narrow set of metrics, like execution time and memory usage). It is obvious that the results of these kinds of benchmarks are rarely representative of real-life applications.
My immediate thought was that a more objective comparison would be useful not only for me but for others as well. But before discussing the details, I’d like to compare several aspects of Elixir and Java that are not easily quantifiable.
Before I started learning Elixir, I used various languages like Java, C, C++, Perl, and Python. Despite that, all of them are imperative languages and Elixir is a functional language, I found the language concepts clear and concise, and – to tell the truth – much less complex than Java. Similarly, Elixir syntax is less verbose and easier to read and see through.
When comparing language complexities, there is an often forgotten, but critical thing: It’s hard to develop anything more complex than a Hello World application just by using the core language. To build enterprise-grade software, you should use at least the standard library, but in most cases, many other 3rd party libraries. They all contribute to the learning curve.
In Java, the standard library is part of the JDK and provides basic support for almost every possible use, but lacked the most important thing, the component framework (like Spring Framework or OSGi), for about 20 years. During that time, several good component frameworks were developed and became widespread, but they all come with different design principles, configuration and runtime behaviour, so for a novice developer, the aggregated learning curve is pretty steep.On the other side, Elixir has the OTP from the beginning, a collection of libraries once called Open Telecom Platform. OTP provides its own component framework which shares the same concepts and design principles as the core language.
I was a bit spoiled by the massive amount of tutorials, guides and forum threads of the Java ecosystem, not to mention the really nice Javadoc that comes with the JDK. It’s not that Elixir lacks the appropriate documentation, there are really nice tutorials and guides, and most of the libraries are comparably well documented as their Java counterparts, but it will take time for the ecosystem to reach the same level of quality. There are counterexamples, of course, the Getting Started Guide is a piece of cake, I didn’t need anything else to learn the language and start active development.
For me as a novice Elixir developer, the most important roadblock was the immature IDE support. Although I understand that supporting a dynamically typed language is much harder than a statically typed one like Java, I’m missing the most basic refactoring support from both the IntelliJ IDEA and VSCode. I know that Emacs offers more features, but being a hardcore vi user, I kept some distance from it.
Fortunately, these shortcomings can be improved easily, and I’m sure there are enough interested developers in the open-source world, but as usual, some coordination would be needed to facilitate the development.
Comparing entire programming models of two very different languages is too much for a blog entry, so I’d like to focus on the language support for performance and reliability, more precisely several aspects of concurrency, memory management and error handling.
The Java Memory Model is based on POSIX Threads (pthreads). Heap memory is allocated from a global pool and shared between threads. Resource synchronisation is done using locks and monitors. A conventional Java thread (Platform Thread) is a simple wrapper around an OS thread. Since an OS thread comes with its own large stack and is scheduled by the OS, it is not lightweight in any way. Java 21 introduced a new thread type (Virtual Thread) which is more lightweight and scheduled by the JVM, so it can be suspended during a blocking operation, allowing the OS thread to mount and execute another Virtual Thread. Unfortunately, this is only an afterthought. While it can improve the performance of many applications, it makes the already complex concurrency model even more complicated. The same is true for Structured Concurrency. While it can improve reliability, it will also increase complexity, especially if it is mixed with the old model. This is also true for the 3rd party libraries, adopting the new features, and upgrading the old deployments will take time, typically years. Until that, a mixed model will be used which can introduce additional issues.
There are several advantages of adopting POSIX Threads, however: it is familiar for developers of languages implementing similar models (e.g. C, C++ etc.), and keeps the VM internals fairly simple and performant. On the other hand, this model makes it hard to effectively schedule tasks and heavily constrains the design of reliable concurrent code. And most importantly, it introduces issues related to concurrent access to shared resources. These issues can materialise in performance bottlenecks and runtime errors that are hard to debug and fix.
The concurrency model of Elixir is based on different concepts, introduced by Erlang in the 80s. Instead of scheduling tasks as OS threads, it uses a construct called “process”, which is different from an operating system process. These processes are very lightweight, operating on independently allocated/deallocated memory areas and are scheduled by the BEAM VM. Scheduling is done by multiple schedulers, one for each CPU core. There is no shared memory, synchronised resource access, or global garbage collection, inter-process communication is performed using asynchronous signalling. This model eliminates the conventional concurrency-related problems and makes it much easier to write massively concurrent, scalable applications. There is one drawback, however: due to these conceptual differences, the learning curve is a bit steeper for developers experienced only with pthreads-related models.
Error recovery and fault tolerance in general are underrated in the world of enterprise software. For some reason, we think that fault tolerance is for mission-critical applications like controlling nuclear power plants, running medical devices or managing aircraft avionics. In reality, almost every business has critical software assets and applications that should be highly available or data, money and consumer trust will be lost. Redundancy may prevent critical downtimes, but no amount of redundancy can mitigate the risk of data corruption or other similar errors, not to mention the cost of duplicated resources.
Java and Elixir handle errors in very different ways. While Java follows decades-old conventions and treats errors as exceptional situations, Elixir inherited a far more powerful concept from Erlang, originally borrowed from the field of fault-tolerant systems. In Elixir, errors are part of the normal behaviour of the application and are treated as such. Since there are no shared resources between processes, an error during the execution of a process does not affect nor propagate to the others; their states remain consistent, so the application can safely recover from the error. In addition, supervision trees can make sure that the failed components will be replaced immediately.
This way, the BEAM VM provides guarantees against data loss during error recovery. But this kind of error recovery is possible only if no errors can leave the system in an inconsistent state. Since Java relies on OS threads, and shared memory can’t be protected from incorrectly behaving threads, under the JVM, there are no such safeties. Although there are Java libraries that provide better fault tolerance by implementing different programming models (probably the most noteworthy is Akka, implementing the Actor Model), the number of 3rd party libraries supporting these programming models is very limited.
For CPU or memory-intensive tasks, Java is a good choice, due to several things, like a more mature Just In Time compiler and tons of runtime optimisations in the JVM, but most importantly, because of its memory model. Since memory allocation and thread handling are basically done on OS level, the management overhead is very low.
On the other hand, this advantage vanishes when concurrent execution is paired with a mixed workload, like blocking operations and data exchange between concurrent tasks. This is the field where Elixir thrives since Erlang and the BEAM VM were originally designed for these kinds of tasks. Due to the well-designed concurrency model, memory and other resources are not shared, requiring no synchronisation. BEAM processes are more lightweight than Java threads, and their scheduling is done at VM level, leading to fewer context switches and better scheduling granularity.
Concurrent operations also affect memory use. Since a Java thread is not lightweight, the more threads are waiting for execution, the more memory is used. In parallel with the memory allocations related to the increasing number of waiting threads, the overhead caused by garbage collection also grows.
Today’s enterprise applications are usually network-intensive. We have separate databases, microservices, clients accessing our services via REST APIs etc. Compared to operations on in-memory data, network communication is many orders of magnitude slower, latency is not deterministic, and the probability of erroneous responses, timeouts or infrastructure-related errors is not negligible. In this environment, Elixir and the BEAM VM offer more flexibility and concurrent performance than Java.
When we talk about scalability, we should mention both vertical and horizontal scalability. While vertical scalability is about making a single hardware bigger and stronger, horizontal scalability deals with multiple computing nodes.
Java is a conventional language in a sense that is built for vertical scaling, but it was designed at a time when vertical scaling meant running on bigger hardware with better single-core performance. It performs reasonably well on multi-core architectures, but its scalability is limited by its concurrency model since massive concurrency comes with frequent cache invalidations and lock contention on shared resources. Horizontal scaling enlarges these issues due to the increased latency. Moreover, since the JVM was also designed for vertical scaling, there is no simple way to share or distribute workload between multiple nodes, it requires additional libraries/frameworks, and in many cases, different design principles and massive code changes.
On the other hand, a well-designed Elixir application can scale up seamlessly, without code changes. There are no shared resources that require locking, and asynchronous messaging is perfect for both multi-core and multi-node applications. Of course, Elixir itself does not prevent the developers from introducing features that are hard to scale or require additional work, but the programming model and the OTP make horizontal scaling much easier.
It is a well-known fact that resource and energy usage are highly correlated metrics. However, there is another, often overlooked factor that contributes significantly to energy usage. The concurrency limit is the number of concurrent tasks an application can execute without having stability issues. Near the concurrency limit, applications begin to use the CPU excessively, therefore the overhead of context switches begins to matter a lot. Another consequence is the increased memory usage, caused by the growing number of tasks waiting for CPU time. Since frequent context switches are also memory intensive, we can safely say that applications become much less energy efficient near the concurrency limit.
Tackling concurrency issues is probably the hardest part of any maintenance task. We certainly collect metrics to see what is happening inside the application, but these metrics often fail to provide enough information to identify the root cause of concurrency problems. We have to trace the execution flow to get an idea of what’s going on inside. Profiling or debugging of such issues comes with a certain cost: using these tools may alter the performance behaviour of the system in a way that makes it hard to reproduce the issue or identify the root cause.
Due to the message-passing concurrency model, the code base of a typical concurrent Elixir application is less complex and free from resource-sharing-related implementation mistakes often poisoning Java code, eliminating the need for this kind of maintenance. Also, the BEAM VM is designed with traceability in mind, leading to lower performance cost of tracing the execution flow.
Most of the enterprise applications heavily depend on 3rd party libraries. In the Java ecosystem, even the component framework comes from a 3rd party, with its own dependencies on other 3rd party libraries. This creates a ripple effect that makes it hard to upgrade just one component of such a system, not to mention the backward incompatible changes potentially introduced by newer 3rd party components. Anyone who has tried to upgrade a fairly large Maven project could tell stories about this dependency nightmare.
The Elixir world is no different, but the number of required 3rd party libraries can be much smaller since the BEAM VM and the OTP provide a few useful things (like the component platform, asynchronous messaging, seamless horizontal scalability, supervision trees), functionality that is very often used and can only be found in 3rd party libraries for Java.
As I mentioned before, I was not satisfied with other language comparisons as they are usually based on simplistic or artificial test cases, and wanted to create something that mimics a common, but easy-to-understand scenario, and then measure the performance and complexity of different implementations. Although real-world performance is rarely just a number, it is a composite of several metrics like CPU and memory usage, I/O and network throughput, I tried to quantify the performance using the processing time, and the time an application needs to finish a task. Another important aspect is code complexity since it contributes to development and maintenance costs. The size and complexity of the implementations also matter since these factors contribute to the development and maintenance costs.
Most real-world applications process data in a concurrent way. These data originate from a database or other kind of backends, microservice or from a 3rd party service. In any way, data is transferred via a network. In the enterprise world, the dominating way of network communication is via HTTP, often part of a REST workflow. That is the reason why I chose to measure how fast and reliable REST clients can be implemented in Elixir and Java, and in addition, how complex each implementation is.
The workflow starts with reading a configuration from a disk and then gathering data according to the configuration using several REST API calls. There are dependencies in between workflow steps, so several of them can’t be done concurrently, while the others can be done in parallel. The final step is to process the received data.
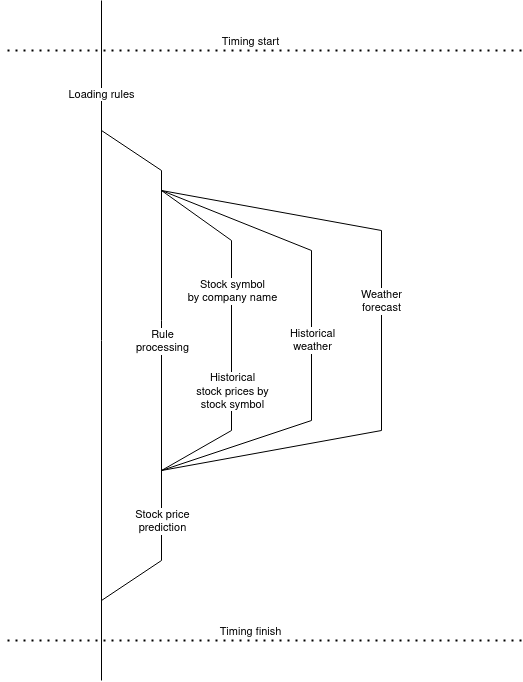
The actual scenario is to evaluate rules, where each rule contains information used to gather data from 3rd party services and predict utility stock prices based on historical weather, stock price and weather forecast data.
Rule evaluation is done in a concurrent manner. Both the Elixir and Java implementation are configured to evaluate 2 rules concurrently.
The Elixir-based REST client is implemented as an OTP application. I tried to minimise the external dependencies since I’d like to focus on the performance of the language and the BEAM VM, and the more 3rd party libraries the application depends on, the more probable there’ll be some kind of a bottleneck.
The dependencies I use:
Each concurrent task is implemented as a process, and data aggregation is done using asynchronous messaging. The diagram below shows the rule evaluation workflow.
There are altogether 8 concurrent processes in each task, one process is spawned for each rule, and then 3 processes are started to retrieve stock, historical weather and weather prediction data.
The Java-based REST client is implemented as a standalone application. Since the Elixir application uses OTP, the fair comparison would be to use some kind of a component framework, like Spring or OSGi, since both are very common in the enterprise world. However, I decided not to use them, as they both would contribute heavily to the complexity of the application, although they wouldn’t change the performance profile much.
Dependencies:
There are two implementations of concurrent task processing. The first one uses two platform thread pools, for rule processing and for retrieving weather data. This might seem a bit naive, as this workflow could be optimised better, but please keep in mind that
The other implementation uses Virtual Threads for rule processing and weather data retrieval.
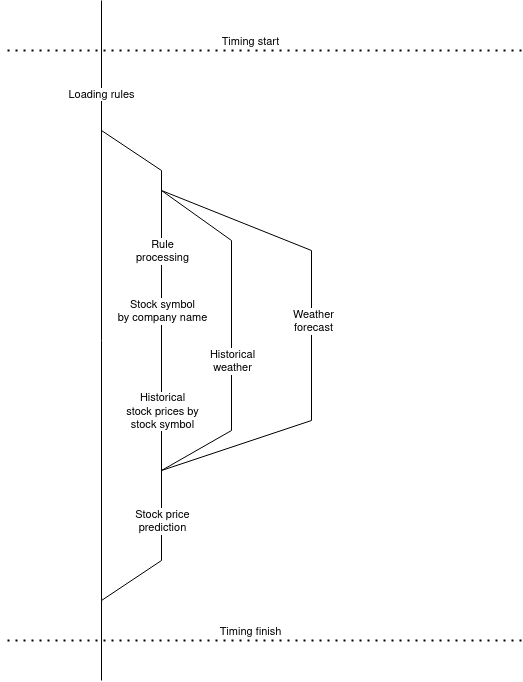
The diagram below shows the rule evaluation workflow.
There are altogether 6 concurrent threads in each task, one thread is started for each rule, and then 2 threads are started to retrieve historical weather and weather prediction data.
Google Compute Node
| Tasks | Elixir | JavaPlatform Threads | JavaVirtual Threads |
| 320 | 2.52 s | 2.52 s | 2.52 s |
| 640 | 2.52 s | 2.52 s | 2.52 s |
| 1280 | 2.51 s | 2.52 s, 11% error | 2.52 s |
| 2560 | 5.01 s | 2.52 s, 7 errors | |
| 5120 | 5.01 s | High error rate | |
| 10240 | 5.02 s | ||
| 20480 | 7.06 s |
| Concurrent tasks per minute | Average | Median | 99th % | Remarks |
| 5 | 2.5 s | 2.38 s | 3.82 s | |
| 10 | 2.47 s | 2.38 s | 3.77 s | |
| 20 | 2.47 s | 2.41 s | 3.77 s | |
| 40 | 2.5 s | 2.47 s | 3.79 s | |
| 80 | 2.52 s | 2.47 s | 3.82 s | |
| 160 | 2.52 s | 2.49 s | 3.78 s | |
| 320 | 2.52 s | 2.49 s | 3.77 s | |
| 640 | 2.52 s | 2.47 s | 3.81 s | |
| 1280 | 2.51 s | 2.47 s | 3.8 s | |
| 2560 | 5.01 s | 5.0 s | 5.17 s | |
| 3840 | 5.01 s | 5.0 s | 5.11 s | |
| 5120 | 5.01 s | 5.0 s | 5.11 s | |
| 10240 | 5.02 s | 5.0 s | 5.15 s | |
| 15120 | 5.53 s | 5.56 s | 5.73 s | |
| 20480 | 7.6 s | 7.59 s | 8.02 s |
| Concurrent tasks per minute | Average | Median | 99th % | Remarks |
| 5 | 2.5 s | 2.36 s | 3.71 s | |
| 10 | 2.54 s | 2.48 s | 3.69 s | |
| 20 | 2.5 s | 2.5 s | 3.8 s | |
| 40 | 2.56 s | 2.45 s | 3.84 s | |
| 80 | 2.51 s | 2.46 s | 3.8 s | |
| 160 | 2.5 s | 2.5 s | 3.79 s | |
| 320 | 2.52 s | 2.46 s | 3.8 s | |
| 640 | 2.52 s | 2.48 s | 3.8 s | |
| 1280 | 2.52 s | 2.47 s | 3.8 s | 11% HTTP timeouts |
| Concurrent tasks per minute | Average | Median | 99th % | Remarks |
| 5 | 2.46 s | 2.49 s | 3.8 s | |
| 10 | 2.51 s | 2.52 s | 3.68 s | |
| 20 | 2.56 s | 2.44 s | 3.79 s | |
| 40 | 2.53 s | 2.46 s | 3.8 s | |
| 80 | 2.52 s | 2.48 s | 3.79 s | |
| 160 | 2.52 s | 2.49 s | 3.77 s | |
| 320 | 2.52 s | 2.48 s | 3.8 s | |
| 640 | 2.52 s | 2.49 s | 3.8 s | |
| 1280 | 2.52 s | 2.48 s | 3.8 s | |
| 2560 | 2.52 s | 2.48 s | 3.8 s | Errors: 7 (HTTP client EofException) |
| 3840 | N/A | N/A | N/A | Large amount of HTTP timeouts |
Under high load, strange things can happen. Concurrency (thread contentions, races), operating system or VM-related (resource limits) and hardware-specific (memory, I/O, network etc.) errors may occur anytime. Many of them cannot be handled by the application, but the runtime usually can (or should) deal with them to provide reliable operation even in the presence of faults.
During the test runs, my impression was that the BEAM VM is superior in this task, in contrast to the JVM which entertained me with various cryptic error messages, like the following one:
java.util.concurrent.ExecutionException: java.io.IOException
at java.base/java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.base/java.util.concurrent.FutureTask.get(FutureTask.java:191)
at esl.tech_shootout.RuleProcessor.evaluate(RuleProcessor.java:38)
at esl.tech_shootout.RuleProcessor.lambda$evaluateAll$0(RuleProcessor.java:29)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:840)
Caused by: java.io.IOException
at java.net.http/jdk.internal.net.http.HttpClientImpl.send(HttpClientImpl.java:586)
at java.net.http/jdk.internal.net.http.HttpClientFacade.send(HttpClientFacade.java:123)
at esl.tech_shootout.RestUtils.callRestApi(RestUtils.java:21)
at esl.tech_shootout.StockService.stockSymbol(StockService.java:23)
at esl.tech_shootout.StockService.stockData(StockService.java:17)
at esl.tech_shootout.RuleProcessor.lambda$evaluate$3(RuleProcessor.java:37)
... 4 more
Caused by: java.nio.channels.ClosedChannelException
at java.base/sun.nio.ch.SocketChannelImpl.ensureOpen(SocketChannelImpl.java:195)Although in this case, I know the cause of this error, the error message is not very informative. Compare the above stack trace with the error raised by Elixir and the BEAM VM:
16:29:53.822 [error] Process #PID<0.2373.0> raised an exception
** (RuntimeError) Finch was unable to provide a connection within the timeout due to excess queuing for connections. Consider adjusting the pool size, count, timeout or reducing the rate of requests if it is possible that the downstream service is unable to keep up with the current rate.
(nimble_pool 1.0.0) lib/nimble_pool.ex:402: NimblePool.exit!/3
(finch 0.18.0) lib/finch/http1/pool.ex:52: Finch.HTTP1.Pool.request/6
(finch 0.18.0) lib/finch.ex:472: anonymous fn/4 in Finch.request/3
(telemetry 1.2.1) /home/sragli/git/tech_shootout/elixir_demo/deps/telemetry/src/telemetry.erl:321: :telemetry.span/3
(elixir_demo 0.1.0) lib/elixir_demo/rule_processor.ex:56: ElixirDemo.RuleProcessor.retrieve_weather_data/3
This exception shows what happens when we mix different concurrency models:
Thread[#816,HttpClient@6e579b8-816,5,VirtualThreads]
at java.base@21/jdk.internal.misc.Unsafe.park(Native Method)
at java.base@21/java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:269)
at java.base@21/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:1758)
at app//org.eclipse.jetty.util.BlockingArrayQueue.poll(BlockingArrayQueue.java:219)
at app//org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.idleJobPoll(QueuedThreadPool.java:1139)
The Jetty HTTP client is a nice piece of code and very performant, but uses platform threads in its internals, while our benchmark code relies on virtual threads.
That’s why I had to switch from JDK HttpClient to Jetty:
Caused by: java.io.IOException: /172.17.0.2:60876: GOAWAY received
at java.net.http/jdk.internal.net.http.Http2Connection.handleGoAway(Http2Connection.java:1166)
at java.net.http/jdk.internal.net.http.Http2Connection.handleConnectionFrame(Http2Connection.java:980)
at java.net.http/jdk.internal.net.http.Http2Connection.processFrame(Http2Connection.java:813)
at java.net.http/jdk.internal.net.http.frame.FramesDecoder.decode(FramesDecoder.java:155)
at java.net.http/jdk.internal.net.http.Http2Connection$FramesController.processReceivedData(Http2Connection.java:272)
at java.net.http/jdk.internal.net.http.Http2Connection.asyncReceive(Http2Connection.java:740)
at java.net.http/jdk.internal.net.http.Http2Connection$Http2TubeSubscriber.processQueue(Http2Connection.java:1526)
at java.net.http/jdk.internal.net.http.common.SequentialScheduler$LockingRestartableTask.run(SequentialScheduler.java:182)
at java.net.http/jdk.internal.net.http.common.SequentialScheduler$CompleteRestartableTask.run(SequentialScheduler.java:149)
at java.net.http/jdk.internal.net.http.common.SequentialScheduler$SchedulableTask.run(SequentialScheduler.java:207)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1583)According to the HTTP 2.0 standard, an HTTP server can send a GOAWAY response at any time (typically under high load, in our case, after about 2000 requests/min) to indicate connection shutdown. It is the client’s responsibility to handle this situation. The HttpClient implemented in the JDK fails to do that internally and it does not provide enough information to make the proper error handling possible.
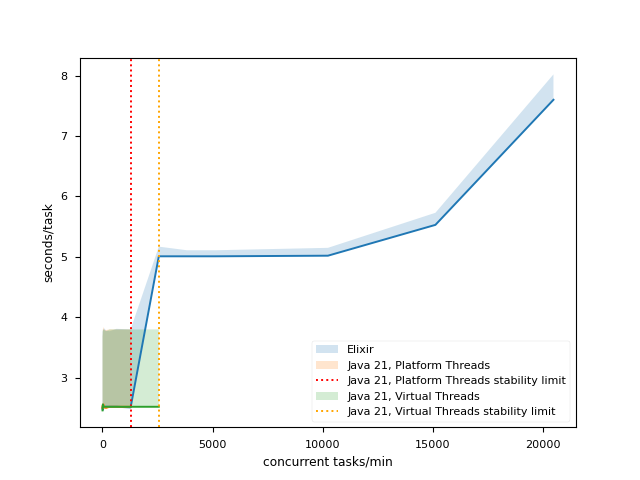
As I expected, both the Elixir and Java applications performed well in low concurrency settings, but the Java application became less stable as the number of concurrent tasks increased, while Elixir exhibited rock-solid performance with minimal slowdown.
The BEAM VM was also superior in providing reliable operation under high load, even in the presence of faults. After about 2000 HTTP requests per second, timeouts were inevitable, but they didn’t impact the stability of the application. On the other hand, the JVM started to behave very erratically after about 1000 (Platform Threads-based implementation) or 3000 (Virtual Threads-based implementation) concurrent tasks.
There are a few widely accepted complexity metrics to quantify code complexity, but I think the most representative ones are the Lines of Code and Cyclomatic Complexity.
Lines of Code, more precisely the Source Lines of Code (SLoC for short) quantifies the total number of lines in the source code of an application. Strictly speaking, it is not very useful as a complexity measure, but it is a good indicator of how much effort is needed to look through a particular codebase. Source Lines of Code is measured by calculating the total number of lines in all source files, not including the dependencies and configuration files.
Cyclomatic Complexity (CC for short) is more technical as it measures the number of independent execution paths through the source code. CC measurement works in a different way for each language. Cyclomatic Complexity of the Elixir application is measured using Credo, and CC of the Java application is quantified using the CodeMetrics plugin of IntelliJ IDEA.

These numbers show that there is a clear difference in complexity even between such small and simple applications. While 9 is not a particularly high score for Cyclomatic Complexity, it indicates that the logical flow is not simple. It might not be concerning, but what’s more problematic is that even the most basic error handling increases the complexity by 3.
These results might paint a black-and-white picture, but keep in mind that both Elixir and Java have their advantages and shortcomings. If we are talking about CPU or memory-intensive operations in low concurrency mode, Java is the clear winner thanks to its programming model and the huge amount of optimisation done in the JVM. On the other hand, Elixir is a better choice for highly concurrent, available and scalable applications, not to mention the field of fault-tolerant systems. Elixir also has the advantage of being a more modern language with less syntactic clutter and less need to write boilerplate code.

Real-time messaging doesn’t fail, it drifts. Under load, small delays reveal if your system can truly scale.

Platform lock-in risks in regulated systems and how to avoid vendor dependency with scalable architecture.

Meet Viktoria Laufer Project Manager at Erlang Solutions. She shares her work on AI projects, team collaboration, and life outside of work.